通过SSH连接到Linux VPS
- 在您的计算机上打开终端或任何SSH客户端(例如Windows中的PuTTY)。
- 使用类似以下的命令连接到服务器:
ssh user@IP_your_server
3. 输入您的密码或使用控制面板中设置的密钥。
额外命令将在本次SSH会话期间执行。
htop的安装与运行
1. 安装htop
在Debian/Ubuntu服务器上,执行以下命令:
sudo apt update
sudo apt install htop
在 CentOS / RHEL / AlmaLinux / Rocky 中:
sudo yum install htop # or dnf install htop
如果没有出现任何错误,该工具将被安装。
2. 启动 htop
在同一 SSH 窗口中,执行以下命令:
htop
屏幕应完全被htop界面占据:
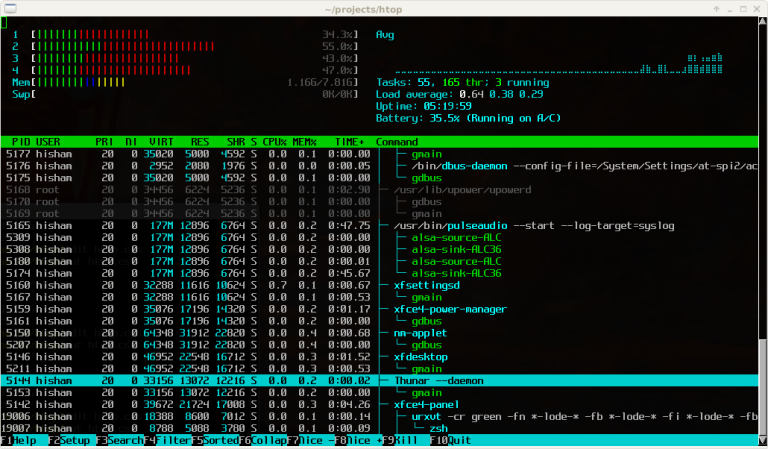
3. 如何解读htop界面
让我们自上而下逐行解析:
- CPU顶部条形图
- 每条彩色条形代表一个独立的vCPU核心。
- 颜色越鲜艳,表示当前负载越高。
- 若一个或多个核心持续处于“100%”状态,则说明处理器过载。
- 内存(Mem)与交换空间条形图
- 显示已使用的RAM总量。
- 若内存几乎耗尽且交换空间被频繁使用,则服务器运行缓慢。
- 右上角
- 平均使用率:显示系统在1、5和15分钟内的平均使用情况。
- 若数值远超vCPU数量(例如双核显示8.0),则表明服务器负载过高。
- 主要进程表
- 各列显示内容:
- PID:进程标识符。
- USER:进程运行用户名。
- %CPU:进程当前占用的CPU资源比例。
- %MEM:占用的RAM比例。
- TIME+:处理器总耗时。
- 命令:运行中的命令/应用程序。
- 弹出描述的底部行
- F6 排序依据:选择排序字段。
- F9 退出:退出当前进程。
- F10 退出:退出htop。
4. 在htop中如何操作?
- 按F6选择按%CPU排序,再按%MEM排序。
- 查看列表最前几行:那里列出了最“耗资源”的进程。
- 若某个进程持续占据列表顶部且CPU占用率达90-100%,则该进程正在拖慢VPS运行速度。
- 若CPU占用率正常,但多个进程的内存占用率过高且几乎耗尽可用内存,则问题源于RAM。
退出htop请按F10或q键。
通过iostat检查硬盘与I/O
若CPU和内存均正常但服务器仍运行缓慢,建议检查硬盘子系统:读写时间及硬盘使用率。
1. 安装iostat(sysstat软件包)
在Debian/Ubuntu系统中:
sudo apt install sysstat
在 CentOS/RHEL 中:
sudo yum install sysstat # или dnf install sysstat
2. 启动 iostat
执行:
iostat -x 5 3
参数说明:
- -x — 高级统计。
- 5 — 结论间隔(5秒)。
- 3 — 重复次数(3次)。
结论示例:
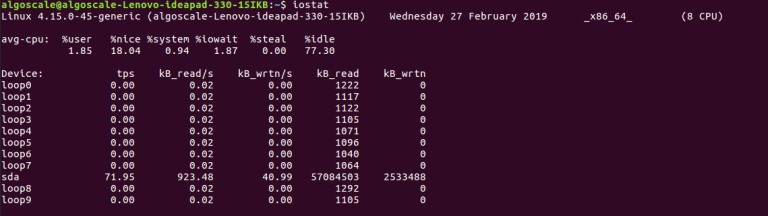
“avg-cpu” 块首先出现,随后是包含硬盘设备的表格。
3. 需要关注哪些字段?
在设备表格(“Device” 行)中,请注意以下要素:
- r/s, w/s:每秒读写操作次数。
- rkB/s, wkB/s:每秒读取/写入速度(千字节)。
- await:I/O操作平均等待时间。
- %util:硬盘满负荷运行时间占比。
近似分析算法:
- 若await值较低(毫秒级)且%util远低于100%,则硬盘运行良好。
- 若await值较高(数十至数百毫秒)且%util持续维持在80%-100%之间,则硬盘处于过载状态。
- 此时htop中CPU可能显示空闲:服务器正在进行硬盘/I/O操作。
在负载期间多次重复执行命令 iostat -x 5 3,观察数值变化趋势。
结合 atop 工具进行综合分析
若需获取整体概览(CPU、内存、硬盘及网络状态),atop 可在单一界面实现多功能监控。
1. atop 安装步骤
适用于 Debian/Ubuntu 系统:
sudo apt install atop
对于 CentOS/RHEL(通常通过 EPEL):
sudo yum install epel-release
sudo yum install atop
2. 上部出口
sudo atop
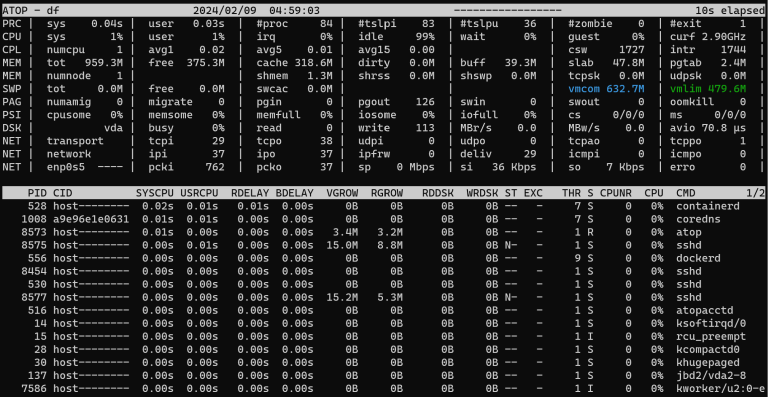
全屏界面打开:
3. atop导航
顶部模块如下:
- PRC:进程概览信息。
- CPU:处理器使用率。
- mem:内存使用率。
- swp:交换空间使用率。
- dsk:硬盘活动。
- net:网络指标。
下方是包含多列的进程列表:CPU使用率、内存使用率、硬盘使用率和网络使用率。
4. atop的典型操作流程
- 观察CPU行:是否持续接近100%使用率?
- mem行:查看内存占用量、可用内存量及缓存使用量。
- dsk行:硬盘总活动量;若数值偏高,请返回重新检查iostat。
- 在进程列表中查找CPU、内存或I/O占用率高的进程:这些通常是负载的根源。
退出atop请按q键。
将上述内容整合为诊断脚本
为使Linux VPS负载监控具有可理解性和可重复性,建议始终遵循相同流程:
疑似过载
网站加载缓慢、API响应延迟、数据库“冻结”。
步骤1:htop
- 运行htop。
- 检查CPU、内存及交换空间使用情况。
- 通过%CPU和%MEM查找“重量级”进程。
步骤2:iostat
- 运行iostat -x 5 3。
- 评估硬盘的await和%util值。
- 若这些数值偏高,则存在硬盘/I/O瓶颈。
步骤3:atop
- 运行sudo atop。
- 检查CPU、mem、dsk和net的摘要行。
- 将其与您在htop和iostat中看到的结果进行比较。
继续
- 如果CPU持续达到上限,请优化应用程序/数据库或增加vCPU数量。
- 如果内存不足,请检查服务配置或添加RAM。
- 若硬盘过载,请更换为更快的 NVMe 硬盘或选择提供更佳硬盘性能的套餐。
何时应升级 VPS 套餐?
若常规监控显示服务器几乎始终处于 CPU、内存或硬盘容量极限运行状态,与持续调整配置相比,升级至更强大的 VPS 套餐更为简便可靠。
结论
监控Linux VPS负载需遵循以下具体步骤:
- htop:显示当前占用CPU和内存的进程。
- iostat:解答“硬盘是否过载”的问题。
- atop:提供所有资源的概览,并帮助关联分散的指标。
遵循上述步骤并参考示意图,即使是缺乏经验的管理员也能在VPS出现问题时立即掌握状况,并判断何种解决方案(优化配置或升级套餐)最为适宜。


